Hat Matrix Leverage Values
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated

11 2 Using Leverages To Help Identify Extreme X Values Stat 501
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated
11 2 Using Leverages To Help Identify Extreme X Values Stat 501

The Plot Of Standardized Residuals Versus Hat Values With A Warning Download Scientific Diagram

Leverage considered large if it is bigger than.
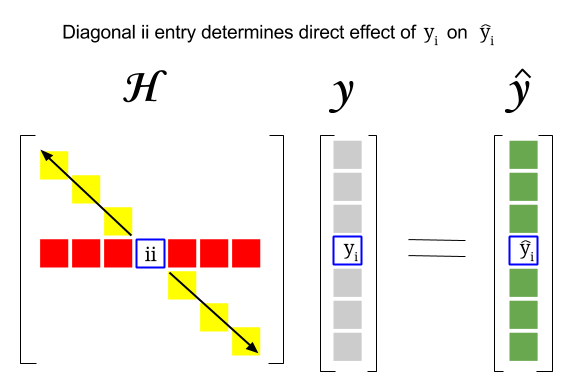
Hat matrix leverage values. The cooks distance is given by the formula. Y j i is the fitted value for the j observation without including the i-th observation in the data that will generate the model. Yˆ is fitted value and e is residual the elements hii of H may be interpreted as the amount of leverage excreted by the ith observation yi on the ith fitted value ˆ yi.
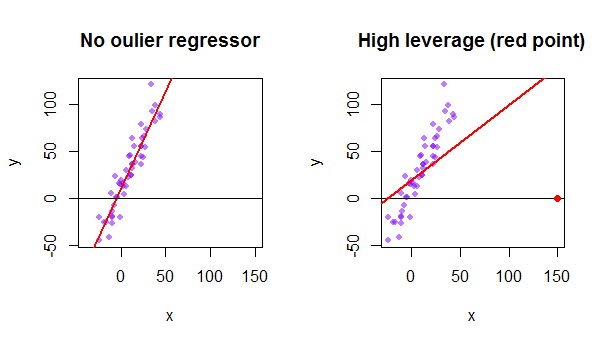
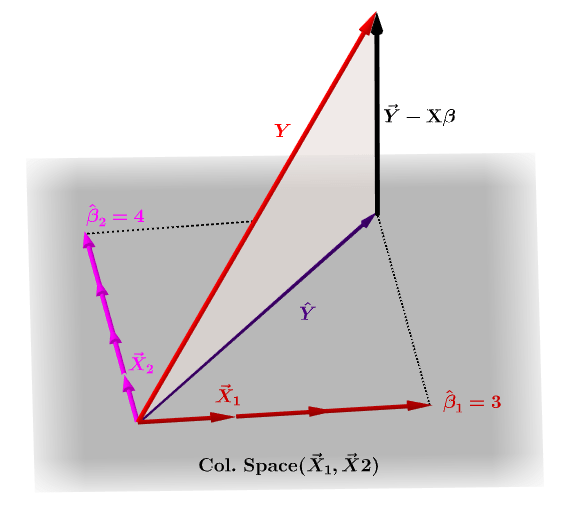
The predicted values ybcan then be written as by X b XXT X 1XT y. Leverage Values Outliers in X can be identified because they will have large leverage values. The hat matrix provides a measure of leverage.
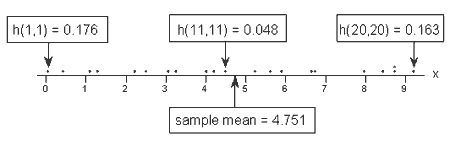
TrH p 1 17 But the trace of any matrix is the sum of its diagonal entries trH Xn i1 H ii 18 so the trace of the hat matrix is the sum of each points leverage. The leverage h i i is a measure of the distance between the x value for the i t h data point and the mean of the x values for all n data points. 3 Draw a histogram stem-and-leaf or other plot of h ii.
The leverage h i i is a number between 0 and 1 inclusive. Where H XXT X 1XT is an n nmatrix which puts the hat on y and is therefore. The function returns the diagonal values of the Hat matrix used in linear regression.
It is useful for investigating whether one or more observations are outlying with regard to their X values and therefore might be excessively influencing the regression results. 2 Moderate leverage if h ii20205 and high leverage if h ii2051. D i j 1 n Y j Y j i 2 p M S E.
The invocation hatvalues vglmObject should return a n times M matrix of the diagonal elements of the hat projection matrix of a vglm object. A vector with the diagonal Hat matrix values the leverage of each observation. It is useful for investigating whether one or more observations are outlying with regard to their X values and therefore might be excessively influencing the regression results.

Hat Matrix And Leverage Matlab Simulink

50 Strategy And Management Models Powerpoint Templates Part 1 Slidesalad Powerpoint Templates Customer Journey Mapping Marketing Analysis

Adl Matrix Corporate Strategy Business Presentation Design Management

Hat Matrix An Overview Sciencedirect Topics

Risk Management Framework Risk Management Corporate Risk Management Risk Management Strategies

Leverage Metrics Compare Owner And Lender Shares Of The Business Business Risk Leverage Business Case
Https Www Stat Washington Edu Pds Stat423 Documents Lecturenotes Notes 423 Ch11 Pdf

Blue Ocean Strategy Value Curve Corporate Strategy Strategy Map Change Management

One Page Culture Roadmap Change Management Internal Communications Leadership

Sample 70 20 10 Innovation Portfolio Matrix Portfolio Management Innovation Management Innovation Strategy

9 5 Identifying Influential Data Points Stat 462

Influence Plot Statistics For Google Sheets

Outliers And Influencers Real Statistics Using Excel

