Hat_matrix_diag

Hat Matrix An Overview Sciencedirect Topics
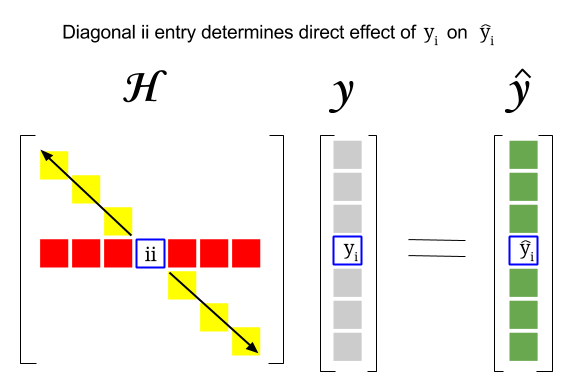
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated

Hat Matrix Freakonometrics

Introduction To The Hat Matrix In Regression Youtube
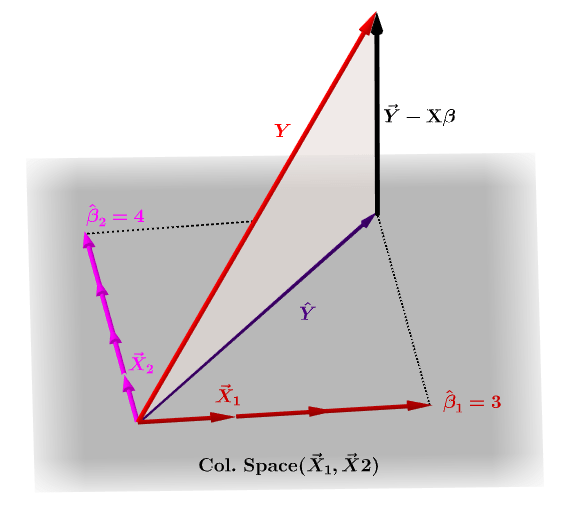
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated

How To Calculate Hat Matrix For Penalized Spline Regressions Cross Validated

EIM weights modelhessian_factorresparams observedFalse this is the same as IRLS weights up to convergence tolerance.
Hat_matrix_diag. Describe count 51000000 mean 0078431 std 0080285 min 0020061 25 0037944 50 0061847 75 0083896 max 0536383 dtype. GLMInfluencehat_matrix_diag source Diagonal of the hat_matrix for GLM. If false then the expected hessian is used.
OLSInfluencehat_matrix_diag source cached attribute diagonal of the hat_matrix for OLS. Temporarily calculated here this should go to model class. H X XTX 1XT.
This returns the diagonal of the hat matrix that was provided as argument to GLMInfluence or computes it using the results method get_hat_matrix. Statsmodelsstatsoutliers_influenceOLSInfluencehat_matrix_diag OLSInfluencehat_matrix_diag source cached attribute diagonal of the hat_matrix for OLS. The hat matrix H is the projection matrix that expresses the values of the observations in the independent variable y in terms of the linear combinations of the column vectors of the model matrix X which contains the observations for each of the multiple variables you are regressing on.
Temporarily calculated here this should go to model class. Naturally y will typically not lie in the column space. The H-M aided designs are efficient and generally as good.
There are three parts to this plot. Import statsmodelsapi as sm Fit linear model to any dataset model smOLSYX results modelfit create instance of influence influence resultsget_influence leverage hat values leverage influencehat_matrix_diag Cooks D values and p-values as tuple of arrays cooks_d influencecooks_distance standardized residuals standardized_residuals. Resid_press cached attribute PRESS residuals.
Second one is the lowess regression line for that. If true then observed hessian is used in the hat matrix computation. Describe count 404000000 mean 0029703 std 0028211 min 0005690 25 0014799 50 0020744 75 0036086 max 0351723 dtype.

Hat Matrix An Overview Sciencedirect Topics
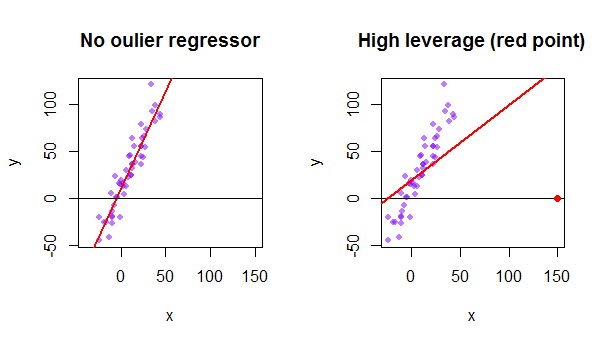
Hat Matrix And Leverages In Classical Multiple Regression Cross Validated

Properties Of Leverage Points In Regression With Proofs Note Typo Youtube

Hat Matrix Freakonometrics

Matrix Hat A Knit Pattern For When You Need To Escape Knitted Hats Hat Knitting Patterns Knitting

Cyber Security Red Team Swords And Matrix Rain Black Bg Sticker Red Team Cyber Security Black Bg

3 20 Points Let H X X X 1x Ernxn Be The Hat Chegg Com

Hat Matrix An Overview Sciencedirect Topics

Threat Intelligence Cyber Security Sticker Happy Sabbath Quotes Cyber Sabbath Quotes

A Message Delivered Ader Adererror Message Spring Summer 2018 Resort Collection Lookbook Web Mobile World Cap Photo Editing Digital Content Ader

Esdep Lecture Note Wg1b Lecture Notes Flexible Architecture Types Of Braces

Fleur De Lis Black Gold Dotted Diagonal Pattern Phone Case Pattern Phone Case Pattern Iphone Case Iphone Case Covers

Cyber Security Badge Seal Red Transparent Sticker Sticker By Fast Designs Transparent Stickers Coloring Stickers Cyber Security

